En la siguiente gráfica podemos observar la evolución del número de clases, métodos y lineas de código en el proyecto en el que me encuentro actualmente.
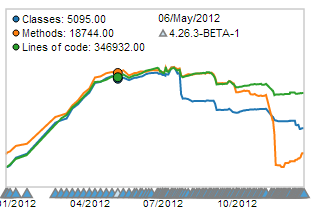
Donde:
- La linea azul indica el número de clases.
- La linea naranja indica el número de métodos.
- Y la linea verde indica el número de lineas.
Como podemos observar no han hecho más que reducirse desde el mes de Junio. Es decir, con menos lineas de código, menos clases y menos métodos estamos en estos momentos implementando más funcionalidad que hace 6 meses (la implementación de nuevas funcionalidades ha continuado durante estos meses). Es sin duda, uno de los logros de los que más contento estoy en este proyecto.
Y me gusta, porque que más se puede pedir: que hacer más y mejor con menos lineas de códigos. Si recordamos el principio KISS ( siglas de Keep It Simple, Stupid):
«La perfección se alcanza, no cuando no hay nada más que añadir, sino cuando ya no queda nada más que quitar.»
El trabajo no ha sido fácil. El principal problema es cambiar la inercia en un proyecto y los programadores. Es muy dificíl en proyectos en los que:
- Lo importante es desarrollar, desarrollar, desarrollar y sacar nuevas funcionalidades al precio que sea.
- Y sobre todo, donde la filosofía que se impone es: «para que voy a cambiar algo que ya funciona«.
En este punto hay que tener claro un par de cosas:
- El concepto de «funciona». Por ejemplo ¿consideráis que funciona una funcionalidad que esta repetida n veces a lo largo del código? Yo estoy convencido de que terminara generando alguna incidencia. ¿Funciona? si, ¿pero durante cuanto tiempo?. ¿En que momento dejaremos de actualizar esa funcionalidad en algunos de los sitios que se repite?.
- No estamos haciendo calidad. Maldigo el significado que se le suele dar a esta palabra, y es que en muchos casos se suele entender por calidad una tarea adicional y por tanto como excusa para evitar los cambios. Estamos hablando de corregir nuestros errores, nuestras limitaciones no de mejorar el código. Calidad es lo que haremos después de esto.
Por eso hay que hay y darse cuenta de que el tamaño si importa y comprender como repercute en nuestro desarrollo:
- Cuando más código, más grande es lo que estamos construyendo y por tanto más difícil de manejar por las herramientas que lo gestionan: el servidor de aplicaciones, el entorno de desarrollo, el entorno de integración continua, etc. Todo va cada vez más lento y es más pesado. Por ejemplo, si utilizas Spring cuantas más clases más tardara en cargarse el contexto.
- Tener nuestro código «bueno» entre miles de lineas de código duplicado o que no se utiliza es una locura para el mantenimiento.
- Y que pasa cuando tenemos que refactorizar. Cambias cosas en sitios en los que no hace falta porque no se esta utilizando (código que no se utiliza). Cambias la misma cosa en varios sitios (código duplicado).
Por tanto, el principal problema para abordar este problema es el cambio de mentalidad. Es lo que más vamos a tener que trabajar. Hay que tener en cuenta este aspecto desde el principio del proyecto y gestionarlo más durante todo el proceso de desarrollo.
A continuación paso a explicar las herramientas que hemos utilizado y me permito ofrecer algunos consejos que nos han resultado útiles.
Para controlar el tamaño de nuestro código hemos trabajado los siguientes puntos:
- Reducir el código que no se utiliza.
- Reducir el código duplicado.
- Y sobre todo, reducir las funcionalidades duplicadas, tanto a nivel de negocio como elementos de la arquitectura.
Para ello nos hemos basado en las siguientes herramientas:
El Sonar.
http://www.sonarsource.org/
Desde el panel de control nos permite:
- Tener identificadas las partes del código donde se producen las malas prácticas que anteriormente hemos mencionado.
- Y nos permite ver la evolución de estas métricas a lo largo de la vida del proyecto.
Esto lo podemos hacer mediante los siguiente widgets:
- Size metrics, nos proporciona información sobre el tamaño del proyecto.
- Timeline, información sobre la evolución de estas métricas.
- Comments & Duplications, código duplicado.
- Useless Code Traker, código que no se utiliza.

Mediante el Size Metrics y el Timeline podemos estar al día de las cifras y de su evolución a lo largo del tiempo.
Bueno, el Timeline es un widget más genérico que se puede configurar para ver la evolución de las tres métricas que nosotros deseamos. En nuestro ejemplo esta configurado para mostrar el número de clases, métodos y lineas.
Mediante Comments & Duplications (¿porque irán juntos comentarios y duplicaciones?) podemos encontrar donde se encuentran los duplicados. En la siguiente imagen se puede observar como nos ofrece la información:
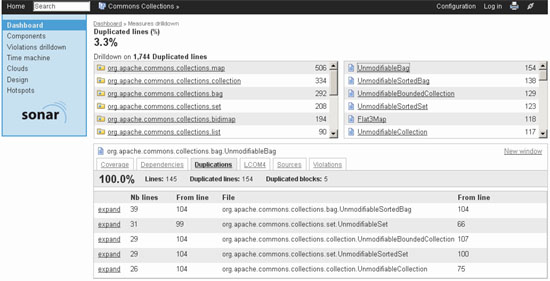
Por defecto, siempre he utilizado la configuración por defecto, aunque parece que se configurar. Para más información sobre el tema: Manage Duplicated Code with Sonar.
Y mediante plugin Useles Code Tracker el código que no se utiliza.
Que si no me equivoco es una mezcla de información que ya tenemos: ofrece la información del código duplicado que se podría eliminar y algunas reglas que vienen con el PMD y SQUID: PMD:UnusedPrivateMethod, SQUID:UnusedPrivateMethod, SQUID:UnusedProtectedMethod.
Para más información os remito a la documentación Useless Code Tracker Plugin.
Plugin PMD/CPD para eclipse.
http://pmd.sourceforge.net/eclipse/
El PMD nos proporciona otra herramienta: CPD que busca código duplicado. Para poder utilizarlo podemos utilizar el PMD como plugin de eclipse y seguir los pasos que indicamos a continuación.
Para ejecutarlo, pulsamos botón derecho sobre un proyecto y seleccionamos la opción PMD | Find Suspect Cut and Paste tal y como podemos ver en la siguiente imagen.

el cual nos crea en un directorio «report» de nuestro proyecto un informe con el nombre de cpd.txt.

Recomiendo ir por partes y dividir el trabajo de eliminar código duplicado en fases. El código duplicado puede estar:
- En la misma clase.
- En clases del mismo paquete o entidades de negocio.
- En paquetes que no tienen nada que ver unos con otros.
Recomiendo empezar por las dos primeras que son relativamente fáciles y que normalmente se resuelve con un refactor que permite extraer el código a un nuevo método o clase.

En cambio el código duplicado entre diferentes paquetes puede implicar cambios más importantes:
- La creación de nuevos paquetes a un nivel alto.
- O delegar parte de la lógica a otros servicios que ya están funcionando y que son los que realmente tienen esa responsabilidad.
Aunque sin duda la mejor técnica para evitar el código duplicado es evitar o tener mucho cuidado con el Copiar y Pegar.
Plugin UCDetector para eclipse.
http://www.ucdetector.org/
Es un plugin para eclipse que nos permite encontrar código muerto. Es decir, clases, métodos y propiedades que no se utilizan.
Se instala como cualquier otro plugin desde la dirección http://ucdetector.sourceforge.net/update.
Y para utilizarlo, botón derecho sobre un proyecto y seleccionar las opción UCDetector | Detect Unnecesarie Code.

Mostrándonos los resultados en las clases afectadas y la vista de problemas de eclipse.

Aunque ojo, porque cuando intentamos detectar código que no se utiliza hay que tener en cuenta que en algunas circunstancias ya que si que se puede estar utilizando:
- Si utilizas Spring recuerda que las implementaciones no se llaman desde el código: son las interfaces.
- Si utilizas reflection evidentemente habrá parte del código que no se referencie.
- Ten cuidado con las clases que ofreces como APIs a terceros. Estas clases como puntos de entrada no tendrán ninguna referencia dentro de nuestro código.
- Etc.
En eclipse la combinación de teclas CONTROL + SIFTH + G.
La cual dada una clase, método o propiedad te indica si esta siendo referenciado o no desde el espacio de trabajo.
Configurar el formateador de código de eclipse para que la guardar elimine código que no se utiliza.
Es sin duda la opción que menos esfuerzo nos requiere. Configuramos el eclipse para que cada vez que guarde el código fuente de una clase elimine los elementos que no se utilicen en dicha clase.
Buscamos en el Eclipse en Preferencias | Java | Editor |Save Actions:
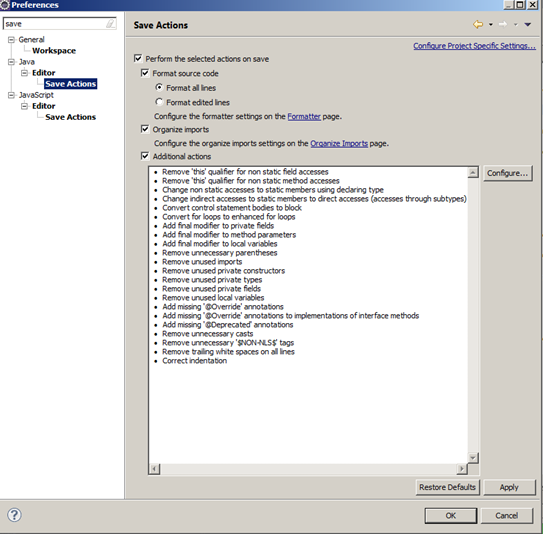
Y configuramos la pestaña de Unnecesary Code:

Ojo con esta configuración, porque puede causar problemillas ya que cada vez que guardas te elimina lo que no estés utilizando en ese momento, aunque lo vayas a utilizar a continuación. Por eso, normalmente los métodos privados no solemos marcarlos.
Otras herramientas que pueden ayudarnos
Antes os he indicado 3 herramientas que nos pueden servir en esta labor y yo creo que son más que suficientes. En cualquier caso aquí os dejo otras que también he probado:
- CheckStyle, al igual que PMD viene con su herramienta para la detección de duplicados.
- Atomiq, que me encanta. Me gusta mucho la representación gráfica en la que muestra el código duplicado. La cuestión es que es de pago pero tiene una versión de evaluación de unos días.

- CodePro AnalytiX, plugin Eclipse de Goolge para analizar código Java que entre otras virtudes tiene la de detectar código duplicado o similar.
- Proguard, es una herramienta para optimizar y ofuscar código java. Entre sus tareas esta la de eliminar clases, métodos, etc, que no se utilicen. Yo no lo he probado y la verdad es que no se como funciona, ya que entiendo que la acción de eliminar código que no se utiliza, forma parte del proceso completo. Pero lo pongo en la lista porque ya he visto a varios autores que lo recomiendan.
- Structure101, es una aplicación de pago que también nos permiten detectar lo que ellos llaman clases huerfanas («Orphans»).
Bueno, ya esta, supongo que aquí faltaría ahora hablar de técnicas de programación o de algunos patrones que nos ayudan a no repetir código. Bueno, para otro artículo!!! en cualquier caso la mejor técnica es la de no copiar y pegar. Y sobre el código que no se utiliza pues no tengamos miedo a eliminarlo lo tenemos en el control de versiones. Ya nos resulta complicado manejar un código relativamente limpio como para que debamos manejarlo acompañado de código que no se utiliza y código duplicado.













Debe estar conectado para enviar un comentario.